2026 AI 软件工程能力大考:从 SWE-bench 到 SWE-bench Pro 的深度解析
overloaded AI 的 AI API 使用建议
overloaded AI 面向需要 OpenAI 兼容接口、Claude/Gemini/GPT 多模型切换、包月额度管理和图像模型调用的用户。阅读本文后,可以结合本站的模型清单、独立使用文档和个人面板,把教程内容直接落到实际调用流程中。
引言:AI 程序员的“终极炼狱”
在软件工程领域,衡量一个 AI 模型是否真正具备“程序员”的素质,已不再仅仅看它能否写出一段简短的算法,而是看它能否在复杂的生产环境中解决真实的 GitHub 问题。SWE-bench 正是为此而生的基准测试。它通过要求模型在隔离的 Docker 容器中修复真实的 Bug 或实现新功能,成为了评估大语言模型(LLM)软件工程能力的金标准。
随着技术的演进,2026 年的基准测试数据显示,AI 正在从“代码补全插件”向“自主智能体(Agent)”跨越,但挑战也随之升级。
榜单现状:Claude 与 GPT 的巅峰对决
根据最新更新的 SWE-bench Verified(人类验证子集)数据,目前的竞争格局呈现出“双雄并立、多方追赶”的态势:
- Claude Opus 4.7 以 82.00% 的解决率稳居榜首,展示了 Anthropic 在长上下文理解与逻辑推理方面的极强优势。
- Gemini 3.1 Pro Preview 緊随其后,达到了 78.80%。
- GPT 5.4/5.5 系列表现稳健,在 78% 左右徘徊。有趣的是,GPT 5.5 在短时间(<15分钟)任务中的解决率高达 92%,展现了极高的响应效率。
任务难度的分水岭
数据揭示了一个有趣的现象:大多数模型在耗时 15 分钟到 1 小时的任务中表现差异最大。能够处理这一难度区间的模型,通常在总榜单上也能获得更高的排名。而对于耗时超过 4 小时的极端复杂任务,即便是顶尖模型如 GPT 5.5 和 Claude Opus 4.7,解决率也仅为 67% 左右。
评测黑科技:mini-swe-agent 框架
为了确保公平性,研究人员采用了 mini-swe-agent 这一极简的“仅 Bash 工具”智能体框架。与许多厂商使用复杂的自定义工具链不同,在该框架下,模型仅被赋予一个工具:Bash。
模型必须像人类开发者一样,使用 grep、find、sed 等标准命令行工具在代码库中导航、搜索相关文件并应用补丁。这种方式极大地排除了“工具辅助”带来的干扰,真实反映了模型本身的命令行熟练度与问题解决策略。
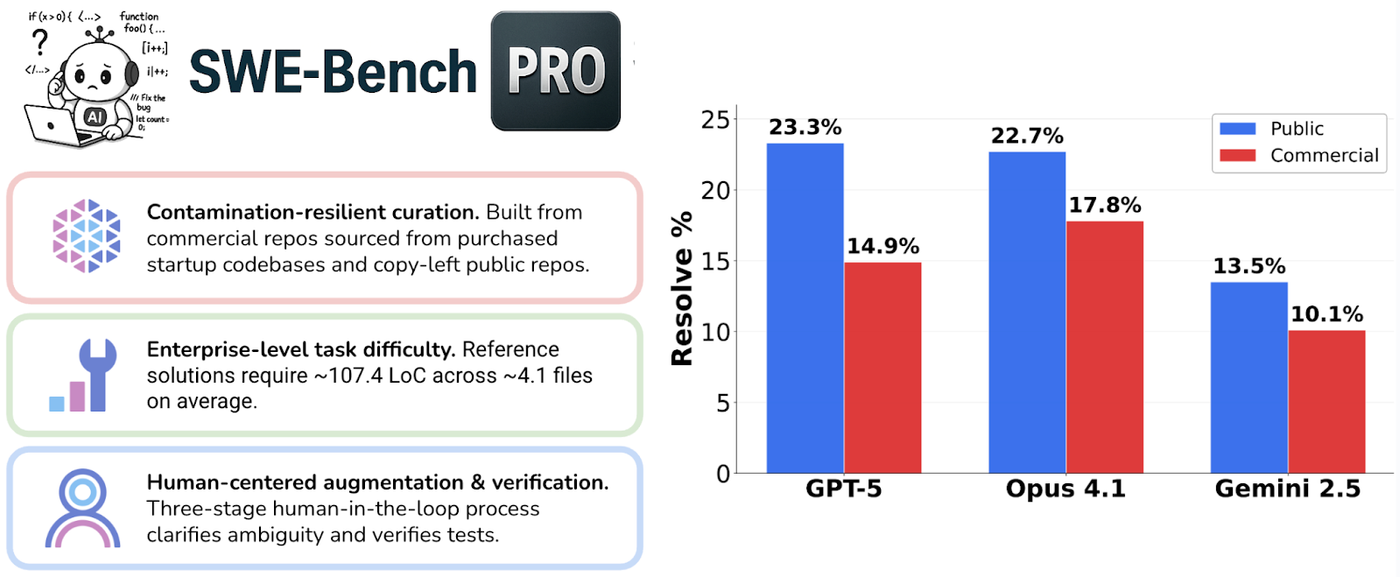
SWE-bench Pro:更严苛的现实挑战
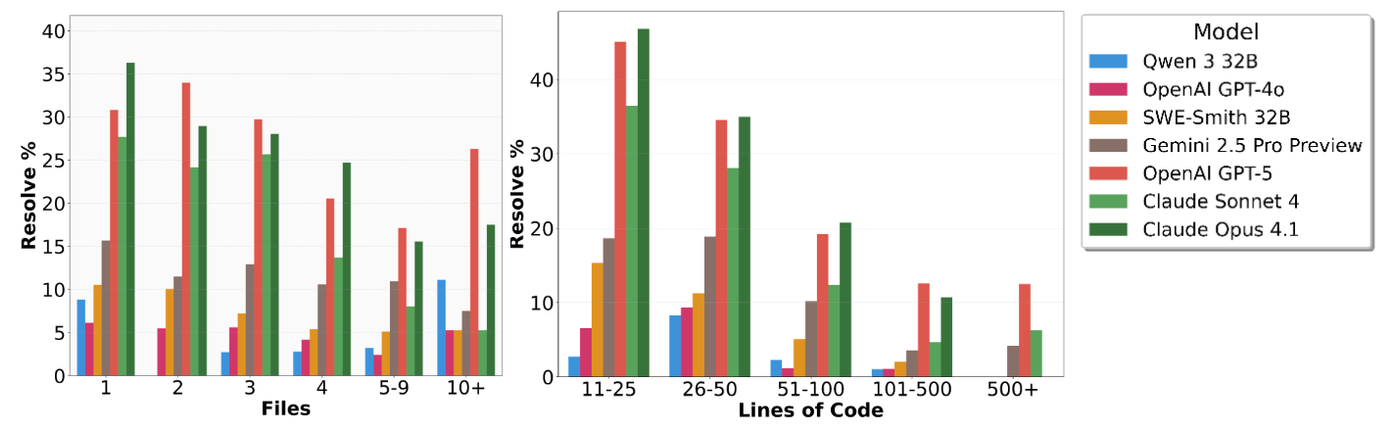
尽管在 Verified 数据集上 AI 已经表现优异,但 Scale Labs 推出的 SWE-bench Pro 却给业界浇了一盆冷水。在 Pro 版本中,即使是最强的 GPT-5.4,解决率也仅为 23.3% 左右,相较于 Verified 版本的 70%+ 出现了大幅滑坡。
为什么 Pro 这么难?
- 反污染设计:Pro 数据集大量采用 GPL 协议的开源仓库和私有闭源仓库。由于法律和访问限制,这些代码极难被包含在模型的训练数据中,从而测试出模型的真本事而非“记忆力”。
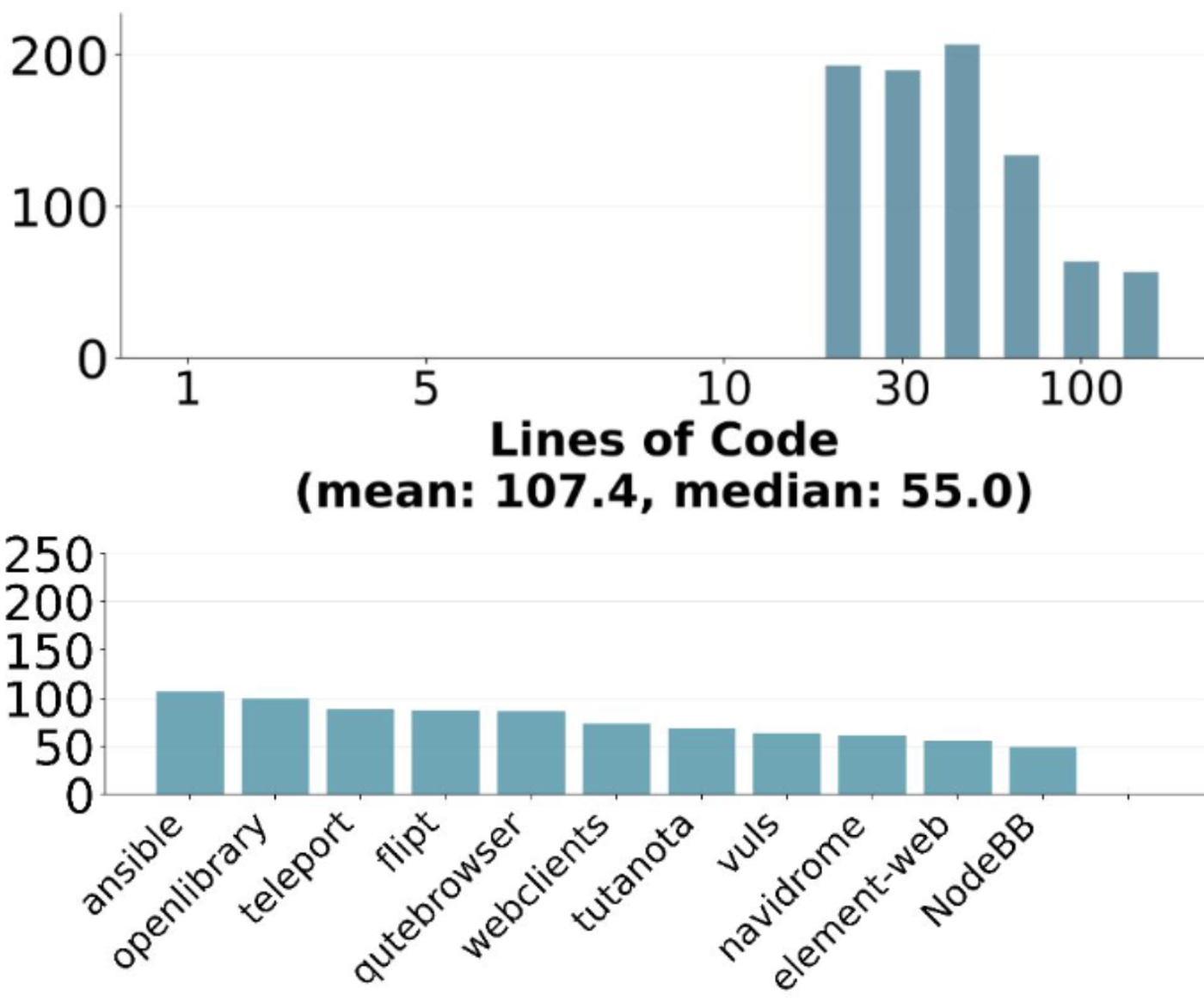
- 更复杂的工程量:平均每个任务涉及 107.4 行代码的修改,且跨越 4.1 个文件。这对模型的长程推理和全局视角提出了极高要求。
- 环境复杂性:从 B2B 平台到开发者工具,Pro 涵盖了更多样化的工业级架构。
关键发现与行业洞察
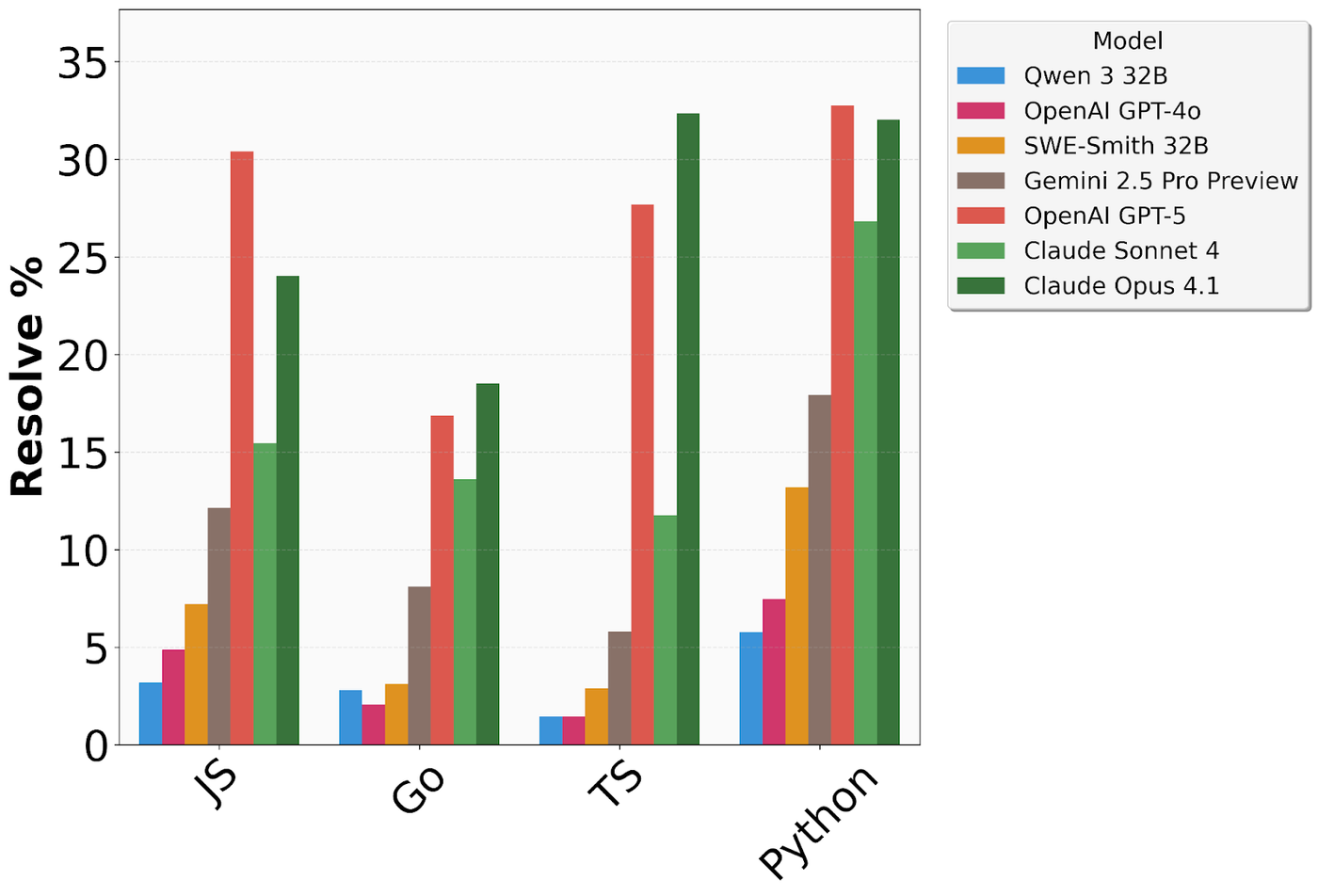
- 闭源模型依然领先:在处理复杂软件工程任务时,闭源模型(Claude, GPT, Gemini)的表现显著优于开源模型(如 Qwen, Llama)。
- 私有数据是试金石:在面对完全未见的私有代码库时,即便是顶尖模型的性能也会下降约 5%-10%,这说明当前的 AI 在面对全新软件架构时仍存在适应成本。
- 编程语言差异:AI 在 Python 和 Go 语言任务上的成功率较高,而在 JavaScript (JS) 和 TypeScript (TS) 上的表现则参差不齐,这可能与语言本身的动态特性及生态复杂度有关。
结语:迈向自主编程的明天
从 SWE-bench 的进化可以看出,AI 的能力正在从“写出能跑的代码”向“维护复杂的系统”演进。虽然在面对大规模、跨文件的复杂工程时,AI 仍面临挑战,但随着推理能力(Reasoning)的进一步增强,我们距离“自动修复生产环境 Bug”的时代已经不再遥远。
未来的开发者或许不再需要亲自修改每一行代码,而是成为 AI 智能体的“主建筑师”,在更高层级上通过指令和代码审查来驱动生产力。