
AI 编程的新巅峰:深度解析 SWE-bench 与 SWE-bench Pro 软件工程基准测试
overloaded AI 的 AI API 使用建议
overloaded AI 面向需要 OpenAI 兼容接口、Claude/Gemini/GPT 多模型切换、包月额度管理和图像模型调用的用户。阅读本文后,可以结合本站的模型清单、独立使用文档和个人面板,把教程内容直接落到实际调用流程中。
AI 编程的新巅峰:深度解析 SWE-bench 与 SWE-bench Pro 软件工程基准测试
在过去的一年里,大语言模型(LLM)在生成代码片段方面表现出色,但将它们应用于处理真实世界、跨文件的复杂软件工程任务仍然是一项巨大挑战。为了衡量这些模型的真正实力,SWE-bench 应运而生。它不仅是一个基准,更是衡量 AI 能否替代或辅助人类工程师解决生产级 GitHub 问题的试金石。
本文将基于最新的测试数据,带您深入了解 SWE-bench 的演进、各大模型的最新表现,以及更严苛的 SWE-bench Pro 为 AI 编程设定了怎样的新门槛。
什么是 SWE-bench?
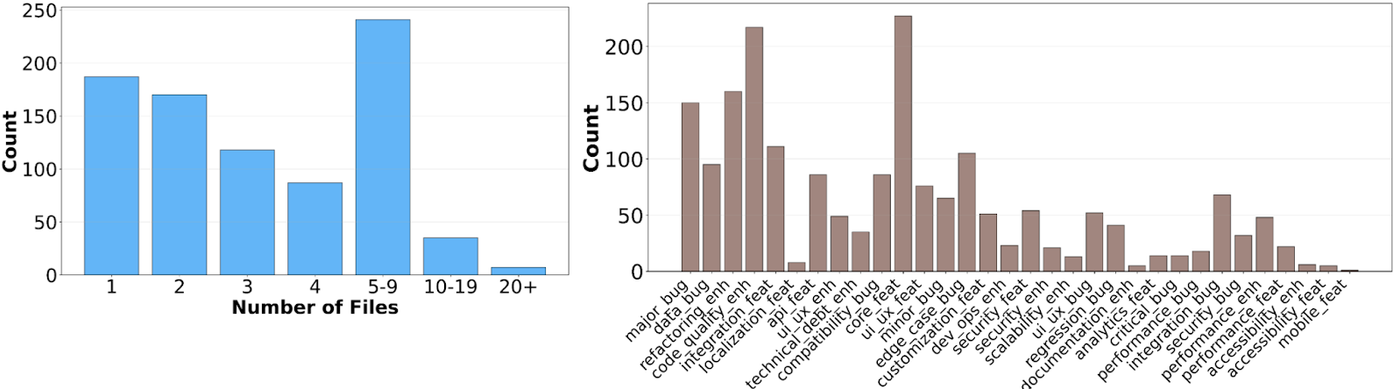
SWE-bench 是由 Jimenez 等人提出的基准测试,旨在评估 LLM 解决真实 GitHub 问题的能力。它包含数百个任务,每个任务都在隔离的 Docker 容器中执行。模型必须生成一个“补丁(patch)”来修复指定的 bug 或实现新功能。成功的标准非常严苛:生成的补丁必须通过该存储库的所有单元测试。
为了确保评估的公平性,最新的测试通常采用 SWE-bench Verified 子集。这是由 OpenAI 在 2024 年 8 月发布的、经过人类专家手动验证的 500 个高质量测试用例,排除了原版中描述模糊或测试不可靠的任务。
当前领跑者:GPT-5.5 与 Claude 4.7 的巅峰对决
根据 Vals.ai 最新的基准测试数据,AI 模型的编程能力正在以惊人的速度提升。在统一使用最简化的 bash-tool-only Agent 框架下,各大模型的表现如下:
- GPT 5.5 以 82.60% 的解决率高居榜首,展现了极强的逻辑推理与任务执行能力。
- Claude Opus 4.7 以 82.00% 的微弱差距紧随其后,两者的表现难分伯仲。
- Gemini 3.1 Pro Preview 表现稳健,以 78.80% 位列第三。
- 国产模型如 GLM 5.1 和 Kimi K2.6 也有不俗表现,解决率均在 70% 以上。
任务难度分析:长程任务仍是软肋
数据表明,模型在解决耗时较短(<15分钟)的任务时成功率极高(如 GPT 5.5 达到 92%),但在处理需要人类工程师 1-4 小时甚至更长时间才能解决的复杂任务时,表现会出现明显下滑。这意味着 AI 在处理跨多文件、需要深层上下文理解的任务时仍有提升空间。
SWE-bench Pro:更真实、更严苛的挑战
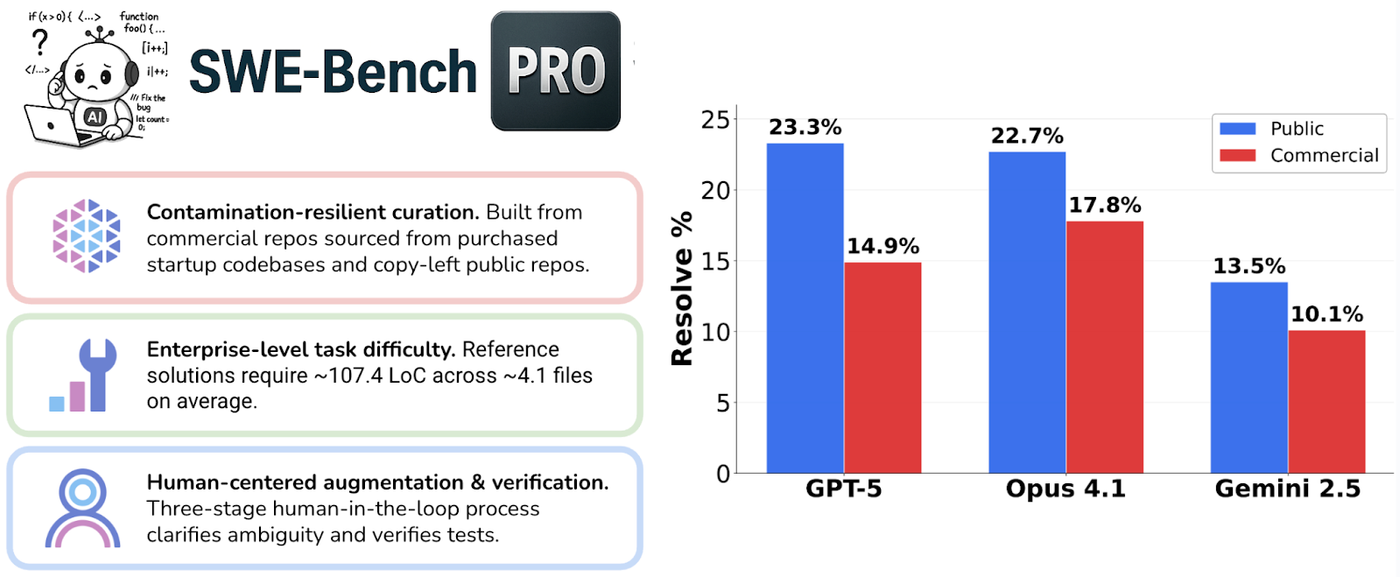
尽管模型在 Verified 版本上取得了 80% 以上的高分,但在现实生产环境中,AI 面临的挑战远比这复杂。Scale AI 推出的 SWE-bench Pro 旨在解决现有基准的局限性,包括数据污染、任务单一和问题过度简化等问题。
SWE-bench Pro 的四大核心改进:
- 防止数据污染:采用具有强 copyleft 许可(如 GPL)的开源库和私有专有代码库,确保模型在训练阶段未见过这些代码。
- 工业级任务多样性:涵盖 B2B 服务、开发者工具和消费级应用,平均每个补丁涉及 107.4 行代码修改,跨越 4.1 个文件。
- 人类专家增强:由专业工程师对问题描述进行补充,确保任务具有可解性,同时保持其技术难度。
- 严格的解决率指标:要求模型不仅要修复 bug,还必须保证不产生任何回归(Regression)。
现实的“冷水”:Pro 版本下的性能表现
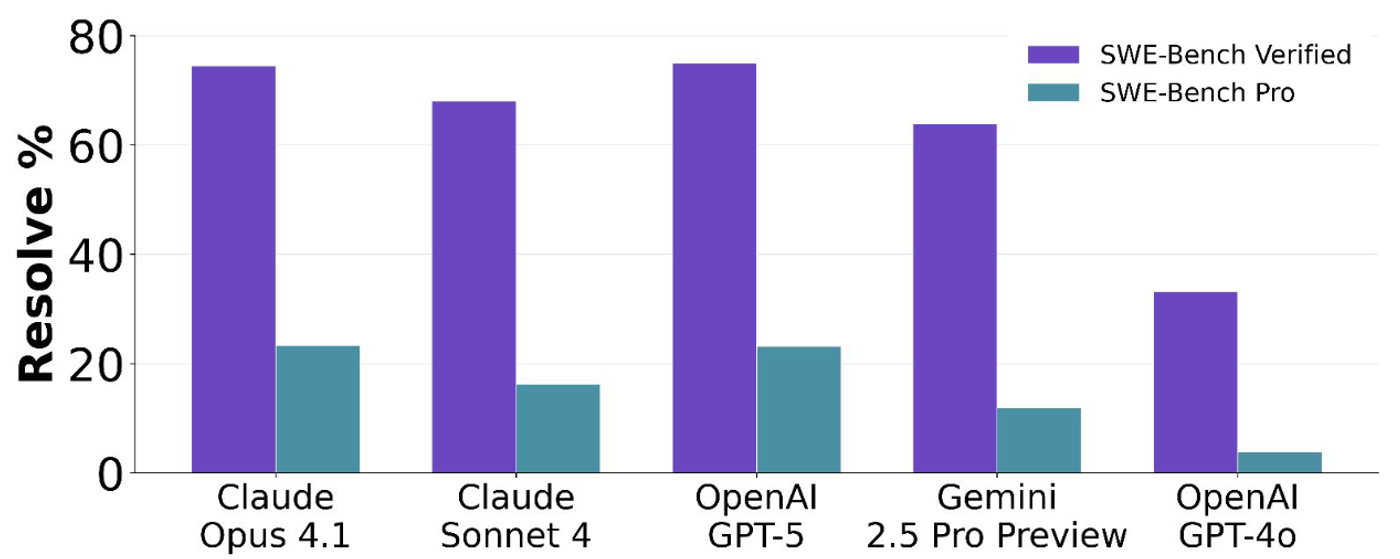
当我们将这些顶级模型置于 SWE-bench Pro 环境中时,解决率出现了显著下降。在 Pro 公开数据集中:
- GPT-5.4 (xHigh) 的解决率为 59.10%。
- Muse Spark 以 55.00% 的成绩成为黑马。
- Claude Opus 4.6 (Thinking) 则取得了 51.90%。
值得注意的是,在完全未见的私有代码库测试中,模型表现进一步下滑。例如,某些模型在公开集能达到 23%,但在私有集仅为 14.9%。这证明了目前 LLM 的编程能力在很大程度上仍依赖于对相似模式的记忆,而非纯粹的通用问题解决能力。
行业洞察与未来趋势
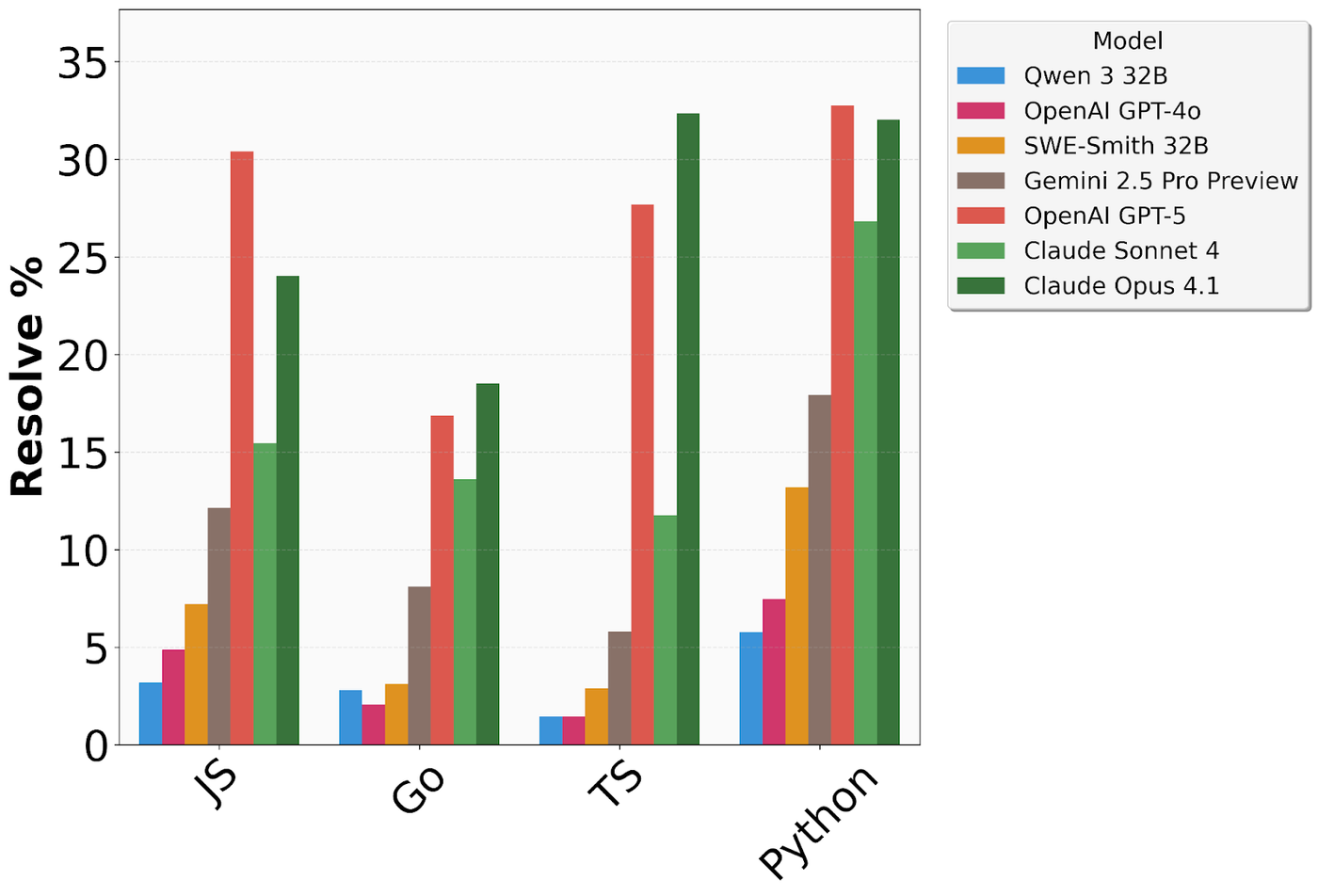
- 闭源模型依然领先:无论是在 Verified 还是 Pro 版本中,OpenAI、Anthropic 和 Google 的顶级闭源模型依然显著领先于开源模型。
- 编程语言差异:模型在 Python 和 Go 上的表现通常优于 JavaScript 和 TypeScript,这可能与训练数据的丰富程度和语言本身的规范性有关。
- Agent 框架至关重要:评估发现,即使是同样的模型,使用不同的 Agent 框架(如定制的工具链)可以带来 10% 以上的性能提升。未来的竞争不仅是模型的竞争,更是“模型+工具”协同能力的竞争。
结语
SWE-bench 系列基准测试记录了 AI 从“代码助手”向“自主工程师”演进的每一个脚印。虽然 GPT-5.5 等模型在 Verified 版本上已接近人类水平,但 SWE-bench Pro 的出现提醒我们:在处理真正复杂、私有且长程的工业级项目时,AI 还有很长的路要走。
对于开发者而言,学会与这些不断进化的模型协作,利用它们解决 80% 的常规 bug,将是未来提升工程效率的关键。